Weiming Zhuang
Weiming Zhuang
Home
Publications
Posts
Patents
computer vision
MixA: A Mixed Attention approach with Stable Lightweight Linear Attention to enhance Efficiency of Vision Transformers at the Edge
We propose MixA, a mixed attention approach for improving ViT efficiency on edge devices while preserving competitive accuracy. By keeping ReLU-based quadratic attention in critical layers and replacing less critical ones with the proposed SteLLA linear attention module, MixA delivers substantial speedups with minimal performance loss.
Sabbir Ahmed
,
Jingtao Li
,
Weiming Zhuang
,
Chen Chen
,
Lingjuan Lyu
PDF
Cite
MAS: Towards Resource-Efficient Federated Multiple-Task Learning
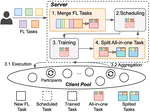
Federated learning (FL) is an emerging distributed machine learning method that empowers in-situ model training on decentralized edge devices. However, multiple simultaneous FL tasks could overload resource-constrained devices. In this work, we propose the first FL system to effectively coordinate and train multiple simultaneous FL tasks. We first formalize the problem of training simultaneous FL tasks. Then, we present our new approach, MAS (Merge and Split), to optimize the performance of training multiple simultaneous FL tasks. MAS starts by merging FL tasks into an all-in-one FL task with a multi-task architecture. After training for a few rounds, MAS splits the all-in-one FL task into two or more FL tasks by using the affinities among tasks measured during the all-in-one training. It then continues training each split of FL tasks based on model parameters from the all-in-one training. Extensive experiments demonstrate that MAS outperforms other methods while reducing training time by 2x and reducing energy consumption by 40%. We hope this work will inspire the community to further study and optimize training simultaneous FL tasks.
Weiming Zhuang
,
Yonggang Wen
,
Lingjuan Lyu
,
Shuai Zhang
PDF
Cite
Code
Project
TARGET: Addressing Catastrophic Forgetting in Federated Class-Continual Learning
This paper focuses on an under-explored yet important problem: Federated Class-Continual Learning (FCCL), where new classes are dynamically added in federated learning. Existing FCCL works suffer from various limitations, such as requiring additional datasets or storing the private data from previous tasks. In response, we first demonstrate that non-IID data exacerbates catastrophic forgetting issue in FL. Then we propose a novel method called TARGET (federatTed clAss-continual leaRninG via Exemplar-free disTillation), which alleviates catastrophic forgetting in FCCL while preserving client data privacy. Our proposed method leverages the previously trained global model to transfer knowledge of old tasks to the current task at the model level. Moreover, a generator is trained to produce synthetic data to simulate the global distribution of data on each client at the data level. Compared to previous FCCL methods, TARGET does not require any additional datasets or storing real data from previous tasks, which makes it ideal for data-sensitive scenarios.
Jie Zhang
,
Chen Chen
,
Weiming Zhuang
,
Lingjuan Lv
PDF
Cite
Project
Toward A Generic Federated Learning Platform Optimized For Computer Vision Applications
Weiming Zhuang
PDF
Cite
DOI
Optimizing Federated Unsupervised Person Re-identification via Camera-aware Clustering
Person re-identification (ReID) is a critical computer vision problem which identifies individuals from non-overlapping cameras. Many recent works on person ReID achieve remarkable performance by extracting features from large amounts of data using deep neural networks. However, the growing awareness of privacy concerns limits the development of person ReID. Prior studies employ federated person ReID to learn from decentralized edges without sharing raw data, but they overlook the variation of identities in different camera views. Concerning this issue, we propose a federated unsupervised person ReID (FedUCA) that leverages camera information to improve learning from decentralized unlabeled data. Specifically, FedUCA jointly learns person ReID models by transmitting training updates instead of raw data. We generate pseudo-labels for unlabeled local datasets on edges by clustering them into multiple groups according to different cameras. We then introduce contrastive learning with an intra-camera loss and an inter-camera loss to enhance the discrimination ability. In extensive experiments on eight person ReID datasets, our proposed approach significantly outperforms the state-of-the-art federated learning based method. It improves performance by 6% to 32% on these datasets, and notably by over 25 % on large datasets. We hope this paper will shed light on optimizing federated learning across a broader range of multimedia applications.
Jiabei Liu
,
Weiming Zhuang
,
Yonggang Wen
,
Jun Huang
,
Wei Lin
PDF
Cite
Project
Project
DOI
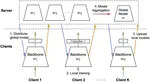
Optimizing Performance of Federated Person Re-identification: Benchmarking and Analysis
We construct a new benchmark to investigate the performance of federated person re-identification (FedReID), which contains nine datasets with different volumes sourced from different domains to simulate the heterogeneous situation in reality. The benchmark analysis reveals the bottlenecks of FedReID under the real-world scenario, including poor performance of large datasets caused by unbalanced weights in model aggregation and challenges in convergence. To address these issues, we propose three optimization methods: 1) We adopt knowledge distillation to facilitate the convergence of FedReID by better transferring knowledge from clients to the server; 2) We introduce client clustering to improve the performance of large datasets by aggregating clients with similar data distributions; 3) We propose cosine distance weight to elevate performance by dynamically updating the weights for aggregation depending on how well models are trained in clients.
Weiming Zhuang
,
Xin Gan
,
Yonggang Wen
,
Shuai Zhang
PDF
Cite
Code
Project
DOI
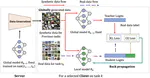
Federated Unsupervised Domain Adaptation for Face Recognition
We propose federated unsupervised domain adaptation for face recognition, FedFR. FedFR jointly optimizes clustering-based domain adaptation and federated learning to elevate performance on the target domain. Specifically, for unlabeled data in the target domain, we enhance a clustering algorithm with distance constrain to improve the quality of predicted pseudo labels. Besides, we propose a new domain constraint loss (DCL) to regularize source domain training in federated learning.
Weiming Zhuang
,
Xin Gan
,
Xuesen Zhang
,
Yonggang Wen
,
Shuai Zhang
,
Shuai Yi
PDF
Cite
Project
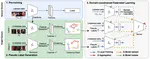
Divergence-aware Federated Self-Supervised Learning
We introduce a generalized federated self-supervised learning (FedSSL) framework and conduct in-depth empirical study of FedSSL based on the framework. Our study uncovers unique insights of FedSSL: 1) stop-gradient operation, previously reported to be essential, is not always necessary in FedSSL; 2) retaining local knowledge of clients in FedSSL is particularly beneficial for non-IID data. Inspired by the insights, we propose a new approach for model update, FedEMA.
Weiming Zhuang
,
Yonggang Wen
,
Shuai Zhang
PDF
Cite
Code
Project
Collaborative Unsupervised Visual Representation Learning from Decentralized Data
We propose a novel federated unsupervised learning framework, FedU, to learn visual representation from decentralized data while preserving data prviacy. To tackle non-IID challenge, we propose two simple but effective methods: 1) We design the communication protocol to upload and update only the online encoders; 2) We introduce a new module to dynamically decide how to update predictors based on the divergence caused by non-IID.
Weiming Zhuang
,
Xin Gan
,
Yonggang Wen
,
Shuai Zhang
,
Shuai Yi
PDF
Cite
Code
Dataset
Project
Poster
Video
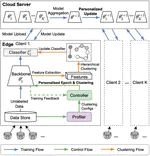
Joint Optimization in Edge-Cloud Continuum for Federated Unsupervised Person Re-identification
We present FedUReID, a federated unsupervised person ReID system to learn person ReID models without any labels while preserving privacy. FedUReID enables in-situ model training on edges with unlabeled data. A cloud server aggregates models from edges instead of centralizing raw data to preserve data privacy. Moreover, to tackle the problem that edges vary in data volumes and distributions, we personalize training in edges with joint optimization of cloud and edge. Specifically, we propose personalized epoch to reassign computation throughout training, personalized clustering to iteratively predict suitable labels for unlabeled data, and personalized update to adapt the server aggregated model to each edge.
Weiming Zhuang
,
Yonggang Wen
,
Shuai Zhang
PDF
Cite
Code
Project
Project
Poster
Video
»
Cite
×